Azure Data Factory - Introduction
Azure is constantly adding new tools to its arsenal and although Azure Data Factory is not new but I have been recently working a lot with it to manage and transform data. In the process I learned a lot about the various capabilities of ADF and also managed to figure out a few tricks. In this series I would share what I have learned so far to help anyone who is taking steps towards a similar journey.
Azure Data Factory allows us to manage the ETL lifecycle for the big data with the flexibility of serverless scaling. Let’s create a Data Factory and I will explain more as we proceed. Navigate to Azure Portal if not already there and search for Data Factories in the search bar. Select Data Factories from the result.
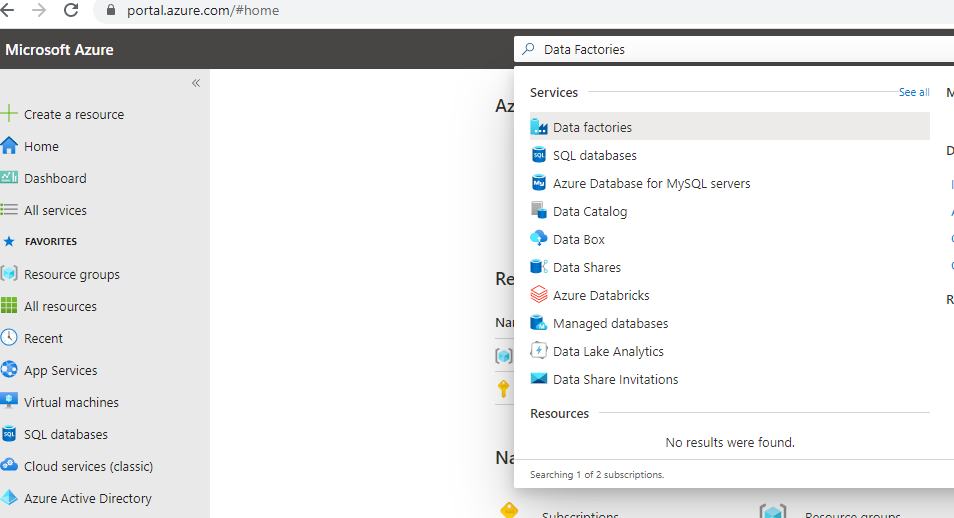
You will be taken to the Data Factories Blade. If you have not created any then you should see a screen like below.
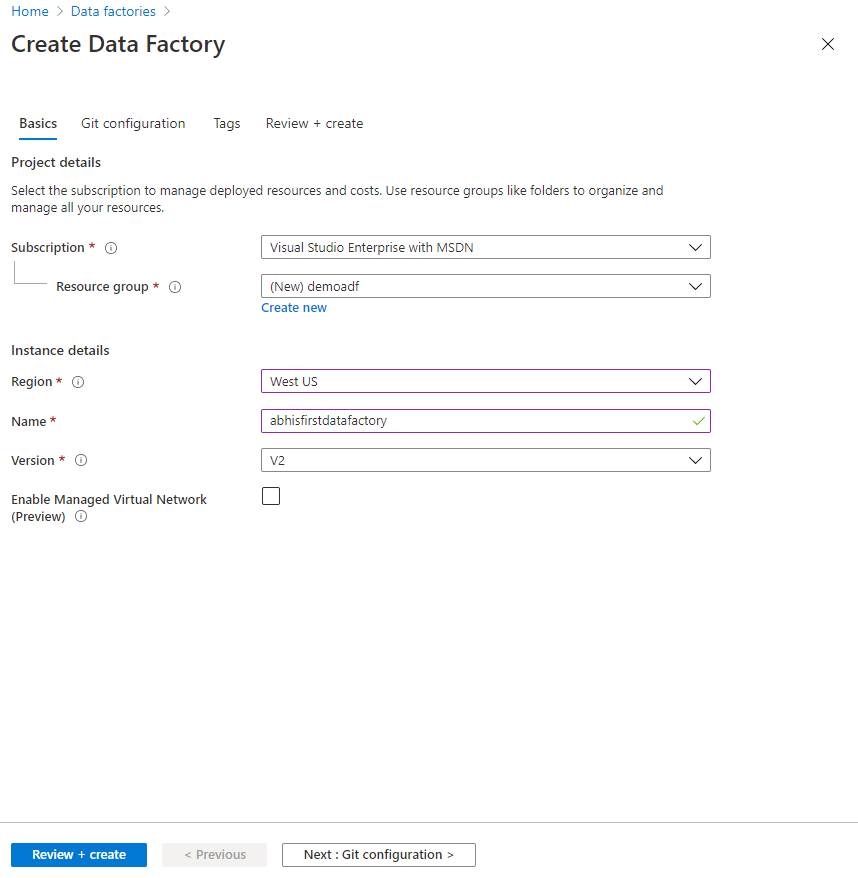
Click on Create Data Factory and you will be taken to the blade like below to enter the details like subscription, resource group, region name and version. As of today V2 is the latest version.
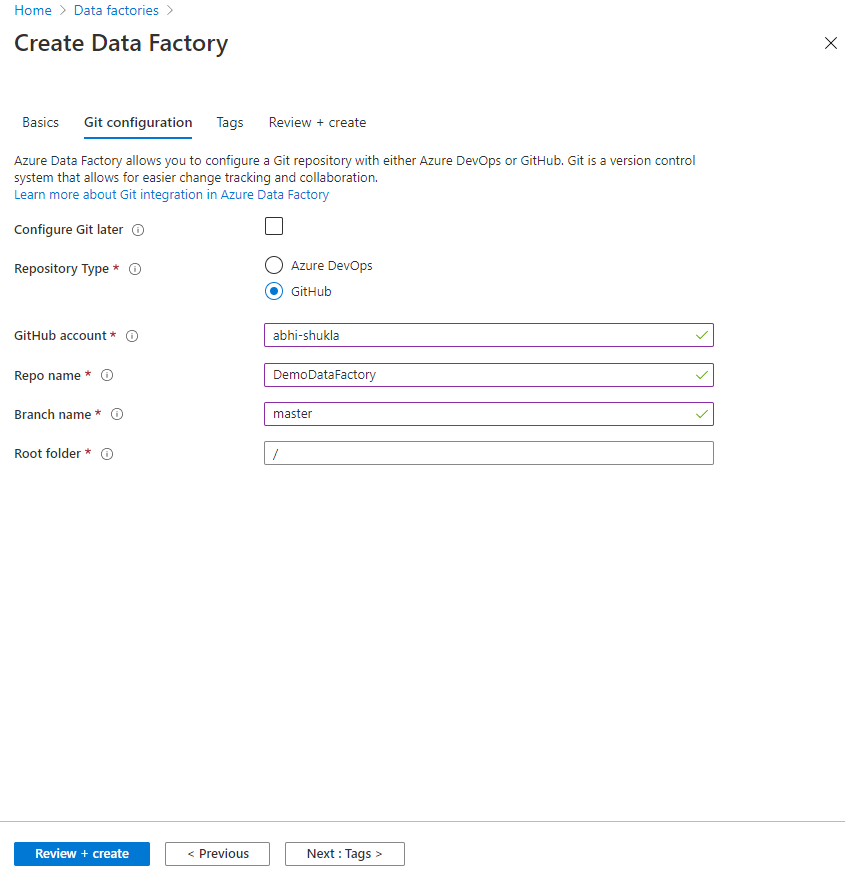
If you like you could enter setup a git repository for the Data Factory. I created a repo and added the details.
The next option is to add tags. I am going to skip that as I am not going to use them in this demo. Once you click next you would see the Review + Create section. If all the validation pass you would be able to Create the Data Factory.
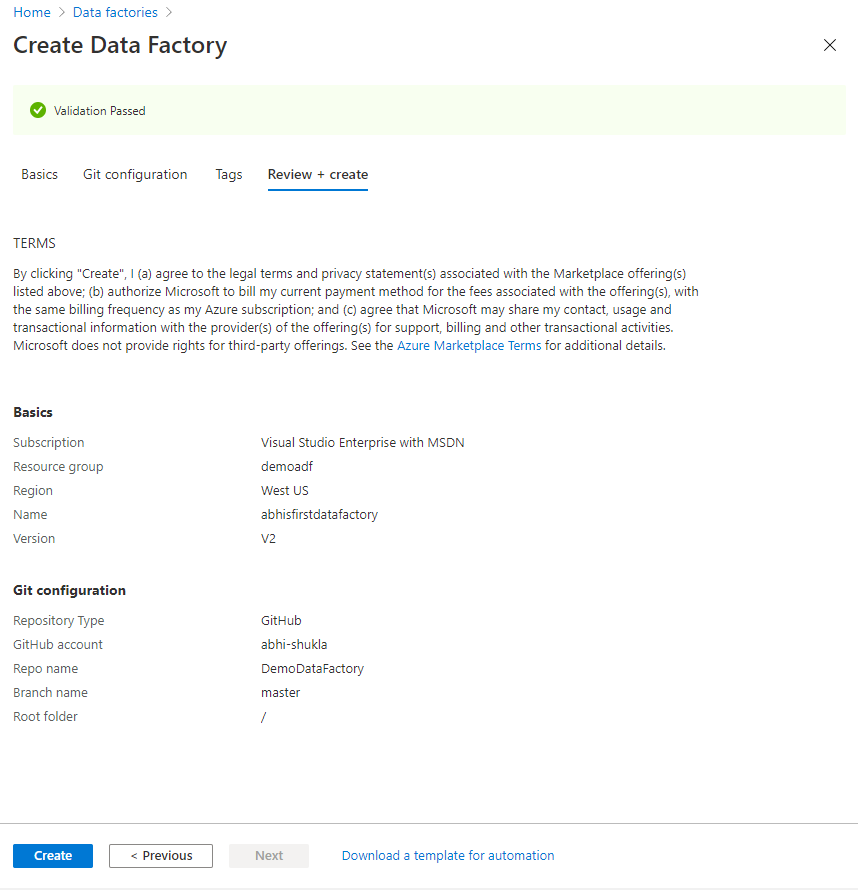
Once you click on create, you would see the deployment starting and once the resource is created you should see something like below.
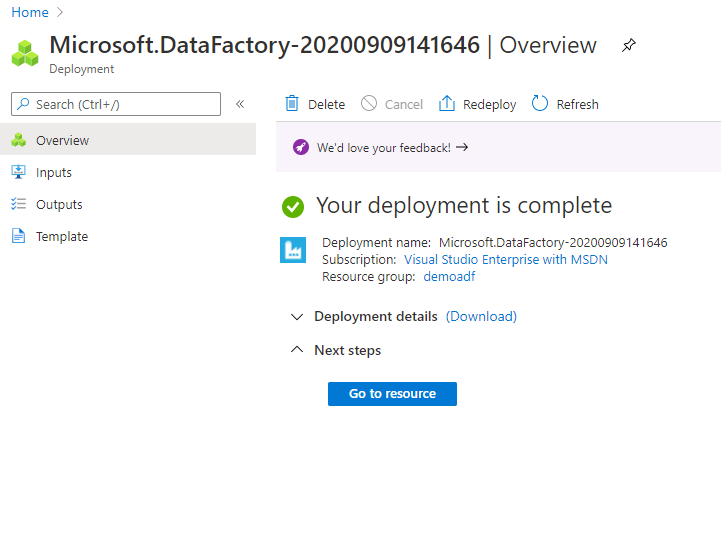
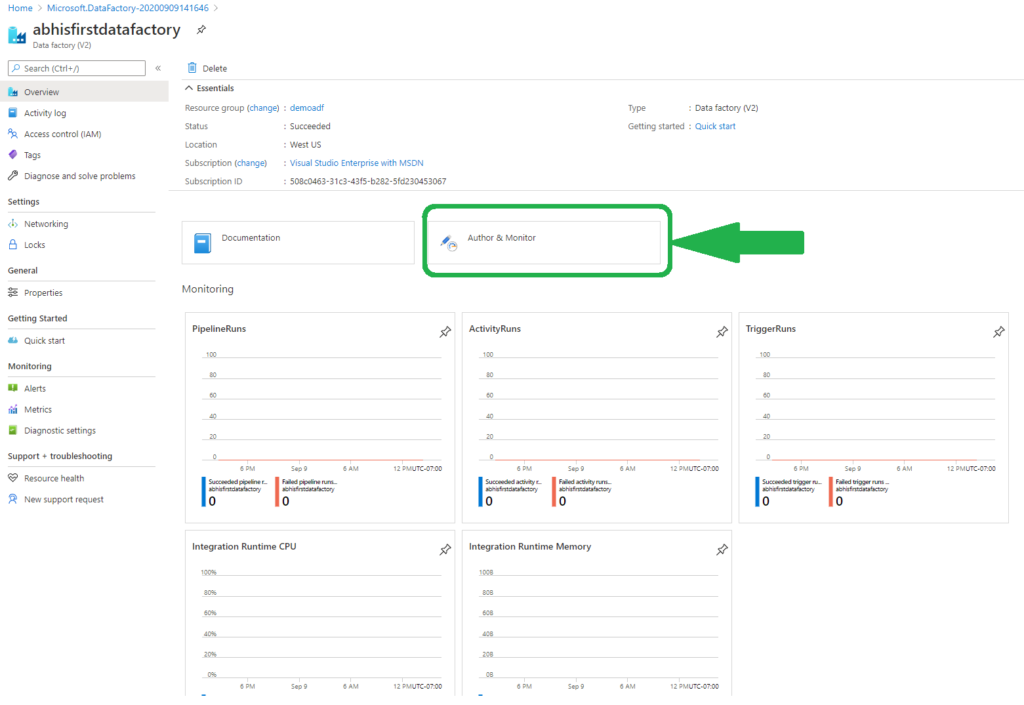
Click on Go to resource and we will be taken to the Data Factory. You will a lot of details about the Data Factory here just like any other Azure Resource. The couple of like that I would like to point out are
- Author and Monitor - this will take to another interface where we will be able to create the Pipelines (scheduled data-driven workflows) that would the ETL for us.
- Documentation - as you already know this would give pretty detailed information about the different aspects of the Data Factories.
I would leave the documentation part up to you to browse through. Let’s navigate to Author and Monitor.
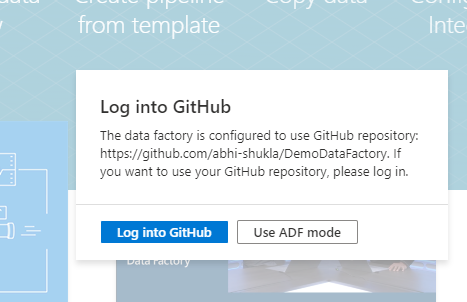
If you added GitHub details while creating the Data Factory then you would be asked to Login to GitHub to provide ADF the necessary permissions.
Once you are done with that you would see a screen like below. The main navigation is in the top left corner of the page. Click on the
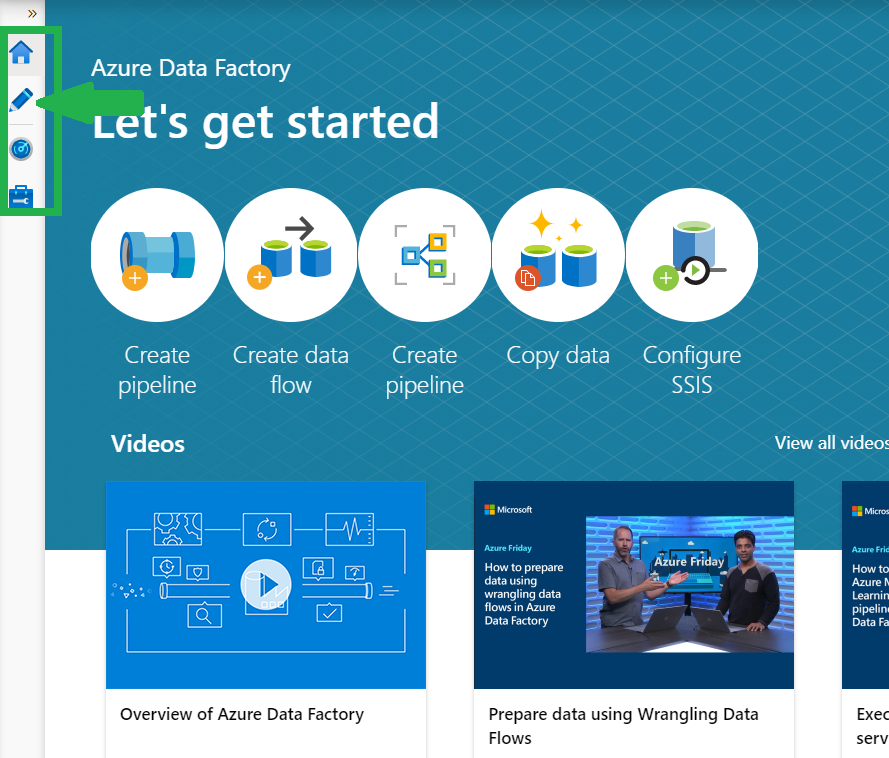
This will take to the screen below. Since this the first time we are we do not have anything at the moment. Let’s go ahead and click on the + in the top left corner and select pipeline.
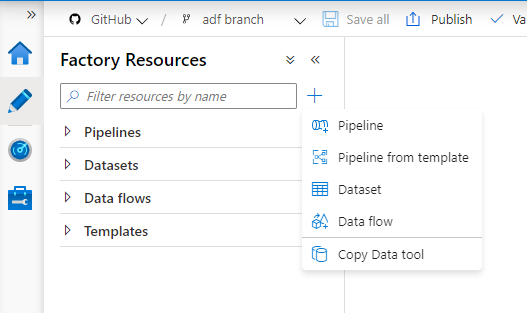
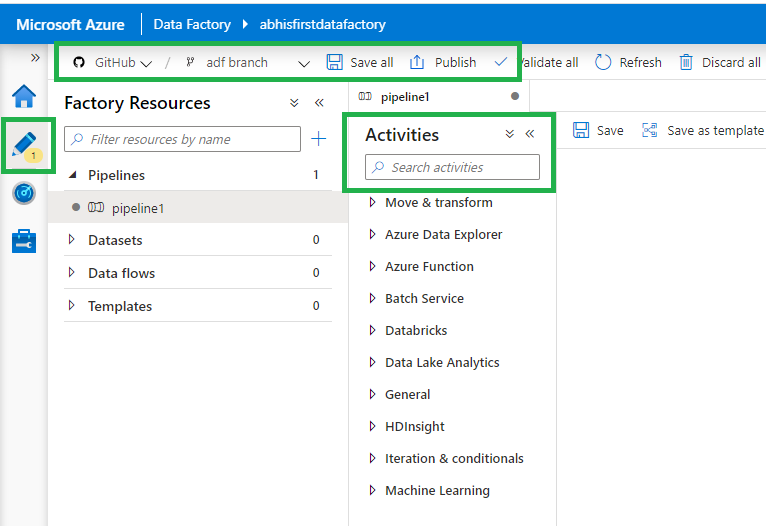
This will create a pipeline and show the Activities toolbar which we will use to drag and drop new activities into the pipeline.
You will also notice that there is yellow indicator with number 1 below the Author Icon. This is because we now have changes that unpublished.
- Your top menu might be a little different if you did not select GitHub for source control.
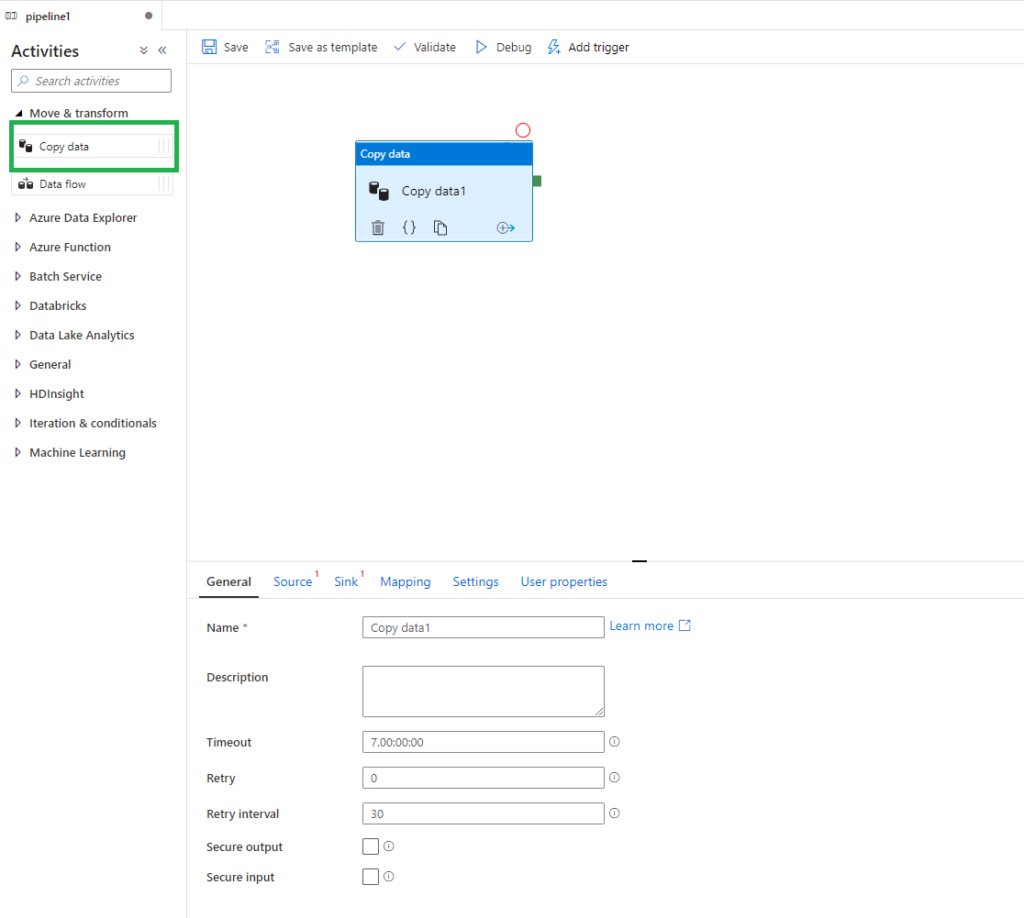
Let’s add a Copy data activity to the pipeline. We can do this by dragging and dropping the Copy data activity from Move & transform onto the central screen.
We will copy data from a SQL Server database to the blob storage. I am not going to cover the creation of SQL Server Database. If you do not have one then you could take this as an assignment to create one. Now let’s link to the SQL Database under the Source. Click on New.
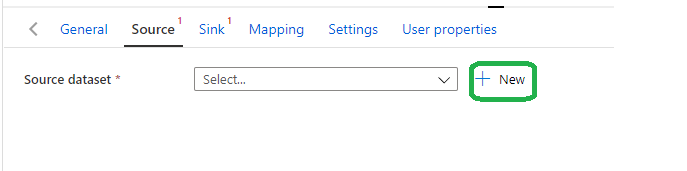
This will open a flyout on the side and we can select SQL as the new Dataset.

We do not have a linked service yet so let’s go ahead and create one which will let us connect to the Sql database we have.
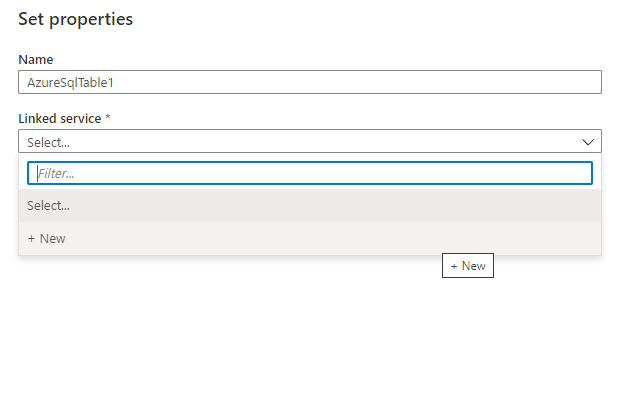
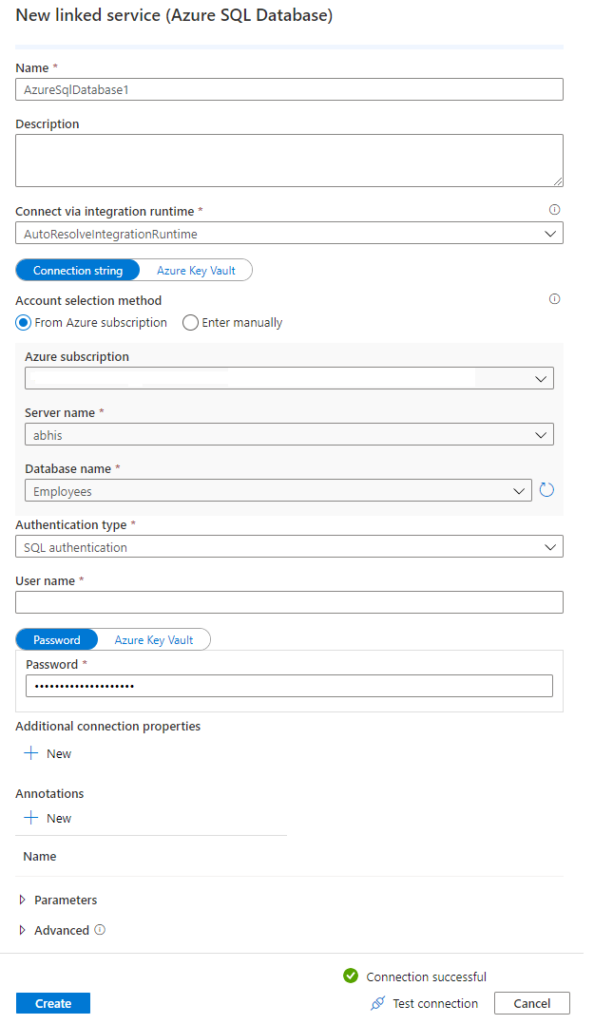
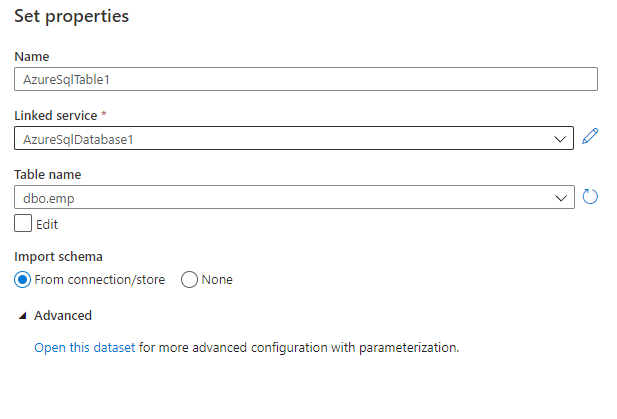
Once we have saved the dataset and linked service information, we should see something like below in the Source section
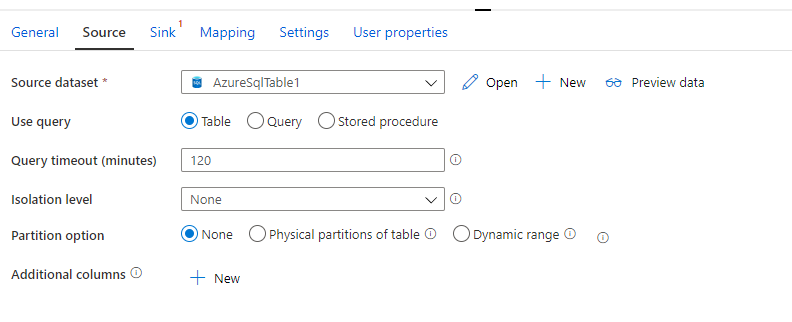
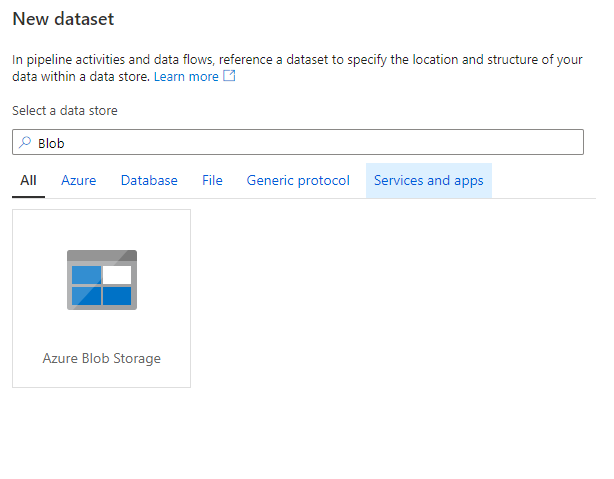
We want to copy the data to Blob storage. Just like SQL storage, I am not going to go into details of creating a blob storage. I hope you are able to set that on your own. If you are unable to do so then please comment on the post and I will add the details for it. Let’s select New and create a new dataset for the blob storage and select the Azure Blob Storage.
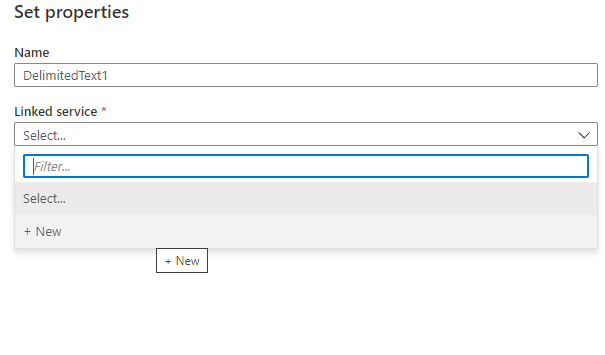
Select the DelimitedText and select New for the creation of Linked service.
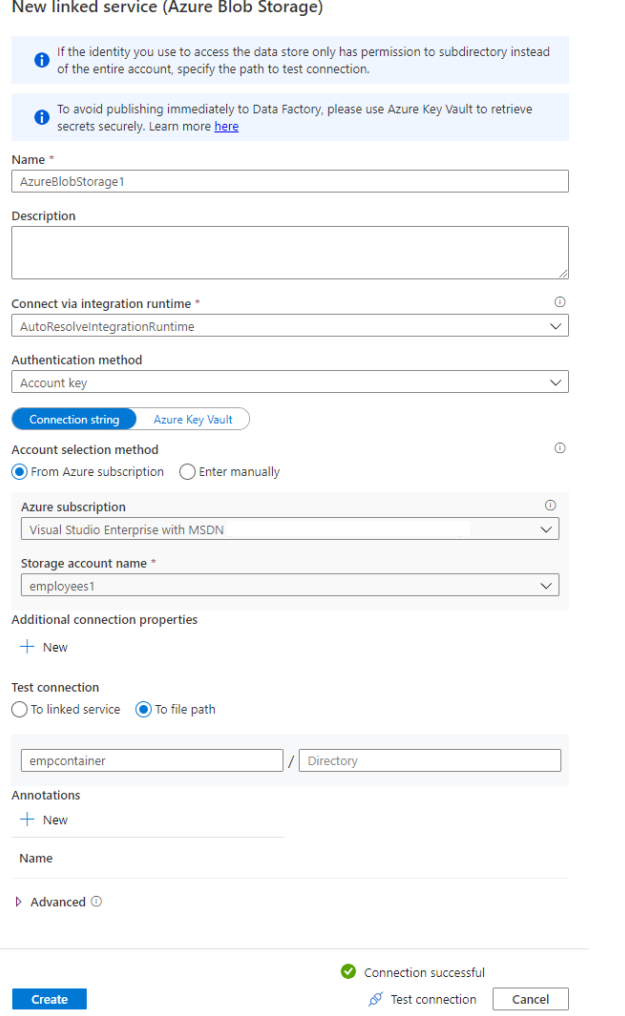
Add the required details for the Azure Blob Storage and make sure you test connection.
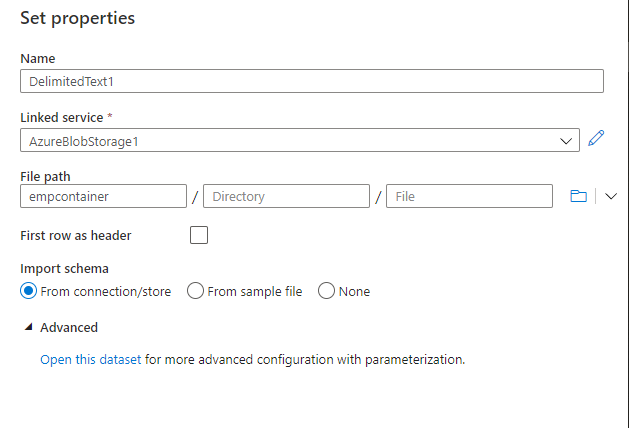
Once we have setup the copy data then click on Debug to run the activity.
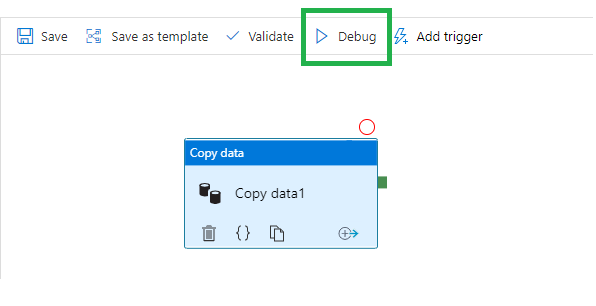
This will run the pipeline in Debug mode and show the run details in the output tab in the bottom. You would be able to see more details about the run when you click on the glasses icon. Also clicking on the two arrow icons you could see the input and output to this activity.

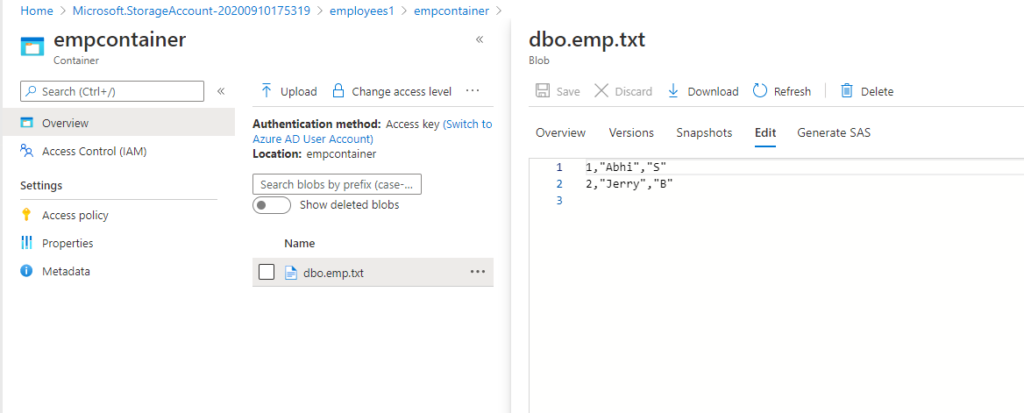
Also when I browse to the container in the Blob Storage I am able to see the data from the SQL database there.
Hope you found this helpful. Feel free to leave feedback and questions.