Journey to RESTfulness - Part 2 of 4
In this post we will derive REST from constraints. However before we do that I would recommend reading the 1st part of the series here.
Deriving REST
Dr. Fielding in his dissertation talks about the method that he would use to define REST. This method is more constraints driven rather than requirements driven. A constraints driven approach identifies the factors that influence system behavior and then we apply the design so that the constraints works with those factors rather than working against them.
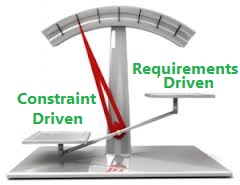 Requiements Vs Constratints
Requiements Vs Constratints
Many software architectures are built and designed for small set of requirements and as we get new requirement we grow our design to incorporate those. The PC architectures follow this pattern because the domain of the architecture and domain of the business are closely coupled. These designs solve programmer problems like encapsulation. These designs are designed and tested in a limited environment and then deployed at production where we discover that there are limitations that keep these designs from being broadly usable apart from the environment for which it was designed.
REST was designed to solve this problem by determining these constraints in a distributed architecture that restrict the design to be usable broadly. Then REST applies these constraints on a working design and thus shaping it incrementally. Hence we end up mapping the business domain on the architecture domain.
So as we conclude that REST is defined as the identifying the forces that are barriers in distributed computing then knowing these barriers might be helpful in understanding the significance of the individual constraints.
Fallacies of Distributed Computing
These are the set of assumptions that L. Peter Deutsch at Sun Microsystems (now Oracle Corporation) originally declared and it states the assumptions that the programmers unaccustomed to distributed applications invariably make. These assumptions ultimately prove false, ensuing either the failure of the system, a considerable reduction in system scope, or in giant, unplanned expenses needed to revamp the system to satisfy its original goals.
The 8 Fallacies of Distributed Computing are as below:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn't change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.So we should design our architecture to work with these forces of nature rather than against them.
Constraints
Let’s have a look at few architectural constraints that define the RESTful style.
Client – Server constraint
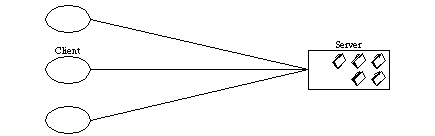
This is one of the fundamental constraint and enforces the constraint in for the client server architecture. The constraint defines all the communication between nodes in a distributed architecture as being between a client and a server. A server is continuously listening for message and when a client sends a message to the server then the server processes it and returns a response. This constraints allows separation the concerns of server and client mainly for User Interface and thus allows different types of client to work with the server and also the client can evolve independently of the server.
 Client Server
Client Server
The guiding forces for the Client-Server constraint are as follows.
- **Network security** is improved as by scoping the connections between clients and servers we can make the system more secure.
- **Administration** **is easier** as by scoping the connections between the clients and servers we limit the responsibilities of client server and hence they are easy to manage.
- **Heterogeneous network** **is workable** by connecting and disconnecting any number of clients on multiple platforms with no impact on the serverThe properties of this constraint are:
- **Client portability is more** because the client structure is independent of the server
- **Scalability is better** because the server does not have to worry about the user interface details
- **Independent client evolution** happens as the server and client are independent.Stateless constraint
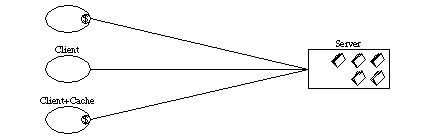
In distributed application the stateless constraint is quite prominent. Stateless constraint does not imply that we should maintain no state of the application but Stateless constraint applies to the communication between the client and server. So the client server interaction must be stateless so that the server is able to process the request with just the information provided by the client request without any context available on the server. The design with Stateless constraint will imply that the state is stored on the client. This design is quite suitable in designs where clients and servers are constantly being added, removed or their network identities are being modified.
 Statelessness
Statelessness
The guiding forces for the Stateless constraint are as follows:
- **Network Reliability** **is improved** by storing the state in the client and we allow the interaction between the client and server to be stateless and this give the application the capability to recover from network errors.
- **Network Topology** **will be simpler** since the state of the client is on the server we can add, remove clients and servers from the network without any corruption of data.
- **Administration** **will be** **simple** when we have stateless interactions.The various properties of this constraint comes are:
- **Visibility** **is improved** since the system does look for any further than the current request so the full nature of the request is known easily.
- **Reliability** of the system **is more** reliable because the system could recover from partial failures.
- **Scalability** **is better** because the server does not have to worry about the state maintenance across various requests and servers.There are a couple of design trade-offs that we would have to do when following this architecture.
- **Network Performance might decrease** as we might me sending more or repetitive data in each request for the server to have enough information to process the request independently.
- **Client consistency might be lost** as the state management is done on the client and the implementation might be different on different platforms.Cache constraint
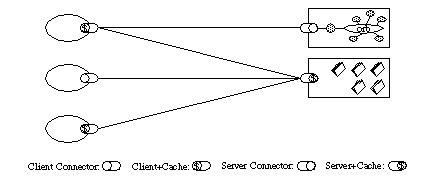
According to REST the response from the server should be implicitly or explicitly labeled as cacheable or not cacheable. When the response is cacheable then the client is allowed to reuse the response in equivalent requests. This could allow our applications to reap the benefits of caching at multiple levels (server, intermediate or client). This will majorly improve the network efficiency.
 Cache
Cache
The guiding forces for the Cache constraint are as follows:
- **Latency is reduced** as some the requests might be served on the client itself and some of them from other caches.
- **Bandwidth consumption is less** since some requests might not even reach the server and served beforehand by cache.
- **Transport cost is reduced** as the number of requests might be reduced.The properties of Cache constraint are:
- **Efficiency is improved** since the application might have less latency and sucks less network.
- **Scalability is improved** since the application is more efficient it could handle more clients.
- **User perceived performance** could be improved when the response from the request is coming from the cache.The design trade-offs that we might have live with, in this architecture is
Decreased reliability on data if the data is stale and differs significantly from the one which would have been provided from the server (if requested).
Uniform Interface constraint
This is the major differentiator between the REST architecture and other network-based architectures. This constraint emphasizes on having a Uniform Interface for all the components in the architecture and could be achieved by applying the generality principle to the component interface and hence simplifying the overall system architecture and improving the visible interactions. So each component talks to the other via standard mechanism. Implementation of decoupling from the service could lead to independent evolution.
 Uniform Interface
Uniform Interface
To achieve the Uniform Interface constraint we need to include the following elements in our design:
- Identification of resources
- Manipulation of resources through representation
- Self-descriptive messages
- Hypermedia as an engine of application state (HATEOAS)The guiding forces for the Cache constraint are as follows:
- **Network reliability is improved** when all the components of the design understand the message sin the same way.
- **Network topology could be simpler** and evolve as the clients and serve communicate with each other following the same interface
- **Administration could be easier** since we could introduce generic tools for network optimization
- **Heterogeneous network** **could be supported better** because the communication interface is the same between different components.The properties of Uniform Interface constraint are as below:
- **Visibility** is more when we are exchanges the same Interface between all the components of the architecture.
- **Evolvability** for each component will be easier as all the component talk the same languageThe design trade-offs that we might have live with, in this architecture is
Decreased efficiency since the data will be transferred in standard format rather than the specific format in which it is needed by the application.
Layered System Constraint
Layered system constraint states that a component in a system should only know about the components of the layer with which it is interacting.
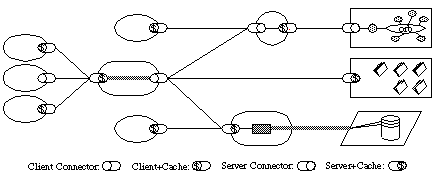 Layered System
Layered System
The guiding forces for the Layered System constraint are as follows:
- **Network topology could be simpler** as the communication is restricted to the layers and when we change the network components then the only the elements that interact with that layer will be impacted.
- **Security will be better** since we layering will allow us to place trust boundaries in layers know the possible components interaction.The properties of Layered System constraint are as below:
- **Scalability** is enormous when we have layered system and modern web is a living example of this.
- **Manageability** is also great since each layer could be managed by different admins and still be perfectly operational and scalable. Example my browser know to manage the connection proxy which is managed by my company which know how to connect to Internet which is managed the ISP and so on and so forth. Each layer is managed by different system with different policies.The design trade-offs that we might have live with, in this architecture is
**Increased latency **since the data might travel more layers as each component will be communicating with the layer it’s supposed to as compared to a direct connection. We can mitigate this trade off by usage of shared caches and intermediate load balancers.
Code on Demand Constraint
This is listed as an optional constraint in Dr. Fielding paper and this might be one of the reasons why it’s not talked about as much. Code on Demand states that along with provides the clients with the data and metadata, the servers could also provide executable code. The idea is to provide the client with readymade features so that they do not need to write or rewrite them.
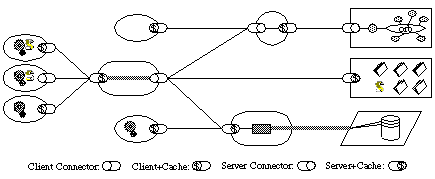 Code On Demend
Code On Demend
The properties of Layered System constraint are as below:
- **Simplicity** is increased since the client have less number of pre written features and these features could be made available by the server.The design trade-offs that we might have live with, in this architecture is
**Reduced visibility **since the clients are downloading the readymade code and features and these might affect caching, manageability and security. So the key rule to applying this constraint is that we should apply this constraint is such a way that the clients who support it should be benefitted by it and the client who do not support this should not break.
Any questions, comments and feedback are most welcome.